Publications
Group highlights
(For a full list see below or go to Google Scholar
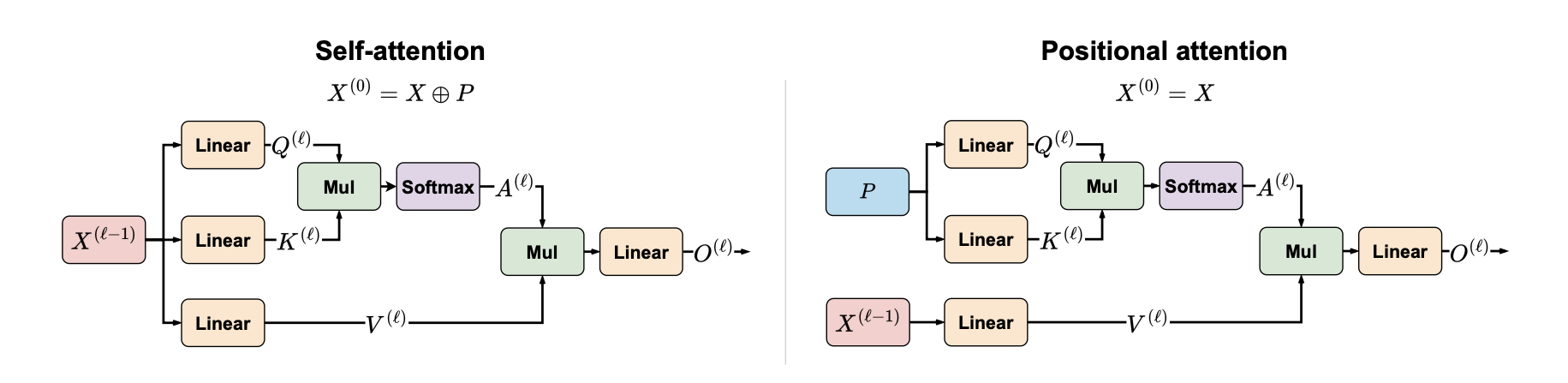
There is a growing interest in the ability of neural networks to execute algorithmic tasks (e.g., arithmetic, summary statistics, and sorting). The goal of this work is to better understand the role of attention in Transformers for algorithmic execution. Its importance for algorithmic execution has been studied theoretically and empirically using parallel computational models. Notably, many parallel algorithms communicate between processors solely using positional information. Inspired by this observation, we investigate how Transformers can execute algorithms using positional attention, where attention weights depend exclusively on positional encodings. We prove that Transformers with positional attention (positional Transformers) maintain the same expressivity of parallel computational models, incurring a logarithmic depth cost relative to the input length. We analyze their in-distribution learnability and explore how parameter norms in positional attention affect sample complexity. Our results show that positional Transformers introduce a learning trade-off, while they exhibit better theoretical dependence on parameter norms, certain tasks may require more layers, which can, in turn, increase sample complexity. Finally, we empirically explore the out-of-distribution performance of positional Transformers and find that they perform well in tasks where their underlying algorithmic solution relies on positional information.
A. Back de Luca, G. Giapitzakis, S. Yang, P. Veličković, K. Fountoulakis
International Conference on Machine Learning (ICML) 2025
![]()
The execution of graph algorithms using neural networks has recently attracted significant interest due to promising empirical progress. This motivates further understanding of how neural networks can replicate reasoning steps with relational data. In this work, we study the ability of transformer networks to simulate algorithms on graphs from a theoretical perspective. The architecture that we utilize is a looped transformer with extra attention heads that interact with the graph. We prove by construction that this architecture can simulate algorithms such as Dijkstra’s shortest path algorithm, Breadth- and Depth-First Search, and Kosaraju’s strongly connected components algorithm. The width of the network does not increase with the size of the input graph, which implies that the network can simulate the above algorithms for any graph. Despite this property, we show that there is a limit to simulation in our solution due to finite precision. Finally, we show a Turing Completeness result with constant width when the extra attention heads are utilized..
A. Back de Luca, K. Fountoulakis
International Conference on Machine Learning (ICML) 2024
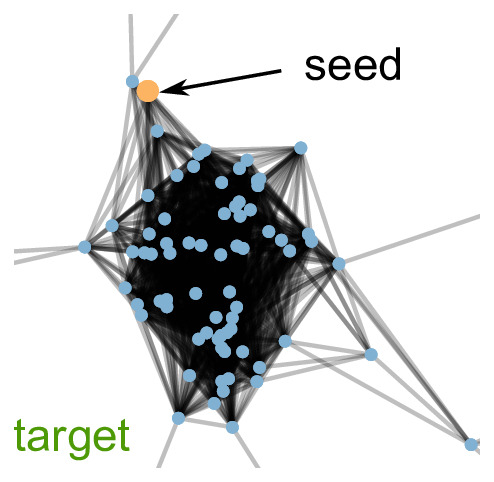
Local graph clustering methods aim to detect small clusters in very large graphs without the need to process the whole graph. They are fundamental and scalable tools for a wide range of tasks such as local community detection, node ranking and node embedding. While prior work on local graph clustering mainly focuses on graphs without node attributes, modern real-world graph datasets typically come with node attributes that provide valuable additional information. We present a simple local graph clustering algorithm for graphs with node attributes, based on the idea of diffusing mass locally in the graph while accounting for both structural and attribute proximities. Using high-dimensional concentration results, we provide statistical guarantees on the performance of the algorithm for the recovery of a target cluster with a single seed node. We give conditions under which a target cluster generated from a fairly general contextual random graph model, which includes both the stochastic block model and the planted cluster model as special cases, can be fully recovered with bounded false positives. Empirically, we validate all theoretical claims using synthetic data, and we show that incorporating node attributes leads to superior local clustering performances using real-world graph datasets.
S. Yang, K. Fountoulakis
International Conference on Machine Learning (ICML) 2023, Oral
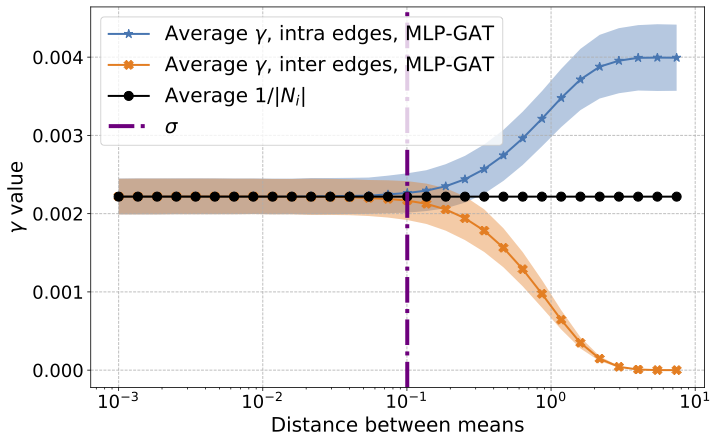
Graph-based learning is a rapidly growing sub-field of machine learning with applications in social networks, citation networks, and bioinformatics. One of the most popular type of models is graph attention networks. These models were introduced to allow a node to aggregate information from the features of neighbor nodes in a non-uniform way in contrast to simple graph convolution which does not distinguish the neighbors of a node. In this paper, we study theoretically this expected behaviour of graph attention networks. We prove multiple results on the performance of the graph attention mechanism for the problem of node classification for a contextual stochastic block model. Here the features of the nodes are obtained from a mixture of Gaussians and the edges from a stochastic block model where the features and the edges are coupled in a natural way. First, we show that in an “easy” regime, where the distance between the means of the Gaussians is large enough, graph attention maintains the weights of intra-class edges and significantly reduces the weights of the inter-class edges. As a corollary, we show that this implies perfect node classification independent of the weights of inter-class edges. However, a classical argument shows that in the “easy” regime, the graph is not needed at all to classify the data with high probability. In the “hard” regime, we show that every attention mechanism fails to distinguish intra-class from inter-class edges. We evaluate our theoretical results on synthetic and real-world data.
K. Fountoulakis, A. Levi, S. Yang, A. Baranwal, A. Jagannath
Journal of Machine Learning Resarch
Best paper award at the GroundedML workshop at ICLR 2022.
Full List
Learning to Add, Multiply, and Execute Algorithmic Instructions Exactly with Neural Networks
A. Back de Luca, G. Giapitzakis, K. Fountoulakis
arXiv:2502.16763
(Preprint)
(Code)
Exact Learning of Permutations for Nonzero Binary Inputs with Logarithmic Training Size and Quadratic Ensemble Complexity
G. Giapitzakis, A. Back de Luca, K. Fountoulakis
3rd Workshop on High-Dimensional Learning Dynamics (HiLD) at ICML 2025
(Preprint)
(Code)
LVLM-COUNT: Enhancing the Counting Ability of Large Vision-Language Models
M. F. Qharabagh, M. Ghofrani, K. Fountoulakis
arXiv:2412.00686
(Preprint)
(Code)
Positional Attention: Expressivity and Learnability of Algorithmic Computation
A. Back de Luca, G. Giapitzakis, S. Yang, P. Veličković, K. Fountoulakis
International Conference on Machine Learning (ICML) 2025
(Preprint)
(Code)
Local Node Embeddings for Heterogeneous Graphs
K. Fountoulakis, D. He
US Patent App. 18/323,877
(Patent)
Analysis of Corrected Graph Convolutions
R. Wang, A. Baranwal, K. Fountoulakis
Conference on Neural Information Processing Systems (NeurIPS) 2024
(Preprint)
Simulation of Graph Algorithms with Looped Transformers
A. Back de Luca, K. Fountoulakis
International Conference on Machine Learning (ICML) 2024
(Preprint)
(Code)
Local Graph Clustering with Noisy Labels
A. Back de Luca, K. Fountoulakis, S. Yang
International Conference on Learning Representations (ICLR) 2024
(Preprint)
(Slides)
(Video)
Optimality of Message-Passing Architectures for Sparse Graphs
A. Baranwal, K. Fountoulakis, A. Jagannath
Conference on Neural Information Processing Systems (NeurIPS) 2023
(Preprint)
(Code)
Weighted flow diffusion for local graph clustering with node attributes: an algorithm and statistical guarantees
S. Yang, K. Fountoulakis
International Conference on Machine Learning (ICML) 2023, Oral
(Preprint)
(Code)
(Video)
On Classification Thresholds for Graph Attention with Edge Features
K. Fountoulakis, D. He, S. Lattanzi, B. Perozzi, A. Tsitsulin, S. Yang
arXiv:2210.10014
(Preprint)
(Code)
Effects of Graph Convolutions in Deep Networks
A. Baranwal, K. Fountoulakis, A. Jagannath
International Conference on Learning Representations (ICLR) 2023, spotlight
(Preprint)
(Code)
(Video)
Graph Attention Retrospective
K. Fountoulakis, A. Levi, S. Yang, A. Baranwal, A. Jagannath
Journal of Machine Learning Resarch
(Preprint)
(Code)
(Video)
Open Problem: Running Time Complexity of Accelerated L1-Regularized PageRank
K. Fountoulakis, S. Yang
Proceedings of Thirty Fifth Conference on Learning Theory (COLT 2022)
Local Hyper-flow Diffusion
K. Fountoulakis, P. Li, S. Yang
Conference on Neural Information Processing Systems (NeurIPS) 2021
(Preprint)
(Code)
(Video)
Graph Convolution for Semi-Supervised Classification: Improved Linear Separability and Out-of-Distribution Generalization
A. Baranwal, K. Fountoulakis, A. Jagannath
International Conference on Machine Learning (ICML) 2021, spotlight
(Preprint)
(Code)
(Video, time 1:03:34)
Targeted Pandemic Containment Through Identifying Local Contact Network Bottlenecks
S. Yang, P. Senapati, D. Wang, C. T. Bauch, K. Fountoulakis
PLOS Computational Biology
(Preprint)
(Code)
p-Norm Flow Diffusion for Local Graph Clustering
K. Fountoulakis, D. Wang, S. Yang
International Conference on Machine Learning (ICML) 2020
(Preprint)
(Code)
(Video)
Flow-based Algorithms for Improving Clusters: A Unifying Framework, Software, and Performance
K. Fountoulakis, M. Liu, D. F. Gleich, M. W. Mahoney
SIAM Review
(Preprint)
(Code)
Statistical Guarantees for Local Graph Clustering (Long version at JMLR)
W. Ha, K. Fountoulakis, M. W. Mahoney
Journal of Machine Learning Research
(Preprint)
Statistical Guarantees for Local Graph Clustering
W. Ha, K. Fountoulakis, M. W. Mahoney
International Conference on Artificial Intelligence and Statistics (AISTATS) 2020
(Preprint)
Parallel and Communication Avoiding Least Angle Regression
S. Das, J. Demmel, K. Fountoulakis, L. Grigori, M. W. Mahoney, S. Yang
SIAM Journal on Scientific Computing
(Preprint)
Locality And Structure Aware Graph Node Embedding
E. Faerman, F. Borutta, K. Fountoulakis, M. W. Mahoney
International Conference on Web Intelligence 2018 (Best student paper award)
(Preprint)
A Flexible Coordinate Descent Method
K. Fountoulakis, R. Tappenden
Computational Optimization and Applications
(Preprint)
Avoiding Synchronization in First-Order Methods for Sparse Convex Optimization
A. Devarakonda, K. Fountoulakis, J. Demmel, M. Mahoney
International Parallel and Distributed Processing Symposium (IPDPS) 2018
(Preprint)
(Video)
Variational Perspective on Local Graph Clustering
K. Fountoulakis, F. Roosta-Khorasani, J. Shun, X. Cheng, M. Mahoney
Mathematical Programming
(Preprint)
(Video)
Capacity Releasing Diffusion for Speed and Locality
D. Wang, K. Fountoulakis, M. Henzinger, M. Mahoney, S. Rao
International Conference on Machine Learning (ICML) 2017
(Preprint)
(Video)
Avoiding communication in primal and dual block coordinate descent methods
A. Devarakonda, K. Fountoulakis, J. Demmel, M. Mahoney
SIAM Journal on Scientific Computing (SISC)
(Preprint)
(Video)
A Randomized Rounding Algorithm for Sparse PCA
K. Fountoulakis, A. Kundu, E. M. Kontopoulou, P. Drineas
ACM Transactions on Knowledge Discovery from Data
(Preprint)
An Optimization Approach to Locally-Biased Graph Algorithms
K. Fountoulakis, D. Gleich, M. Mahoney
Proceedings of the IEEE
(Preprint)
(Video)
Performance of First- and Second-Order Methods for L1-Regularized Least Squares Problems
K. Fountoulakis, J. Gondzio
Computational Optimization and Applications
(Preprint)
(Code)
A Second-Order Method for Strongly-Convex L1-Regularization Problems
K. Fountoulakis, J. Gondzio
Mathematical Programming
(Preprint)
Parallel Local Graph Clustering
J. Shun, F. Roosta-Khorasani, K. Fountoulakis, M. Mahoney
Proceedings of the VLDB Endowment (VLDB) 2016
(Preprint)
A Preconditioner for a Primal-dual Newton Conjugate Gradients Method for Compressed Sensing Problems
I. Dassios, K. Fountoulakis, J. Gondzio
SIAM Journal on Scientific Computing (SISC)
(Preprint)
(Code)
Matrix-free interior point method for compressed sensing problems
K. Fountoulakis, J. Gondzio, P. Zhlobich
Mathematical Programming Computation
(Preprint)
(Code)
Higher-Order Methods for Large-Scale Optimization
K. Fountoulakis
Kimon Fountoulakis’ PhD Thesis